
What are Canonical Tags? – The Complete Guide (2023)
Estimated reading time: 5 minutes
When it comes to search engine optimization, a term that you may have heard is Canonical Tags. But what is it exactly? Canonicals are an essential element of SEO.
Knowing how to use them properly can help you receive better search engine rankings, prevent duplicate content, and improve user experience on your website.
In this guide, we'll explain everything you need to know about canonical URLs, including what they are, what they look like, why they're important for SEO and the best practices for implementing them.
Ogilvy MarTech is a marketing technology solution provider based in Sri Lanka. We are an award-winning web design and development company with over 10 years of experience. We specialize in Technical SEO, SEO consulting, SEO Audits, and more. If you're seeking SEO services, get in touch with our team of SEO specialists!
What are canonical tags?
Canonicals or Canonical tags are HTML elements that tell search engines which page is the source of content, even if that content appears on multiple pages.
To understand it better, imagine having a product listing that appears on several pages on your website. The product description, image, and other details are all the same, but the page URLs differ.
When search engines come across multiple pages with the same content, they mistakenly identify them as duplicate content.
To avoid this complication, these tags help search engines recognize the source of the content. In addition, these tags also ensure search engines understand the original and preferred version of a specific webpage when there are multiple URLs with similar or identical content.
What does a canonical tag look like?
This is an example of what a canonical tag looks like:
It's an HTML element that goes into the head section of a webpage. Here is an example of what it looks like in code:
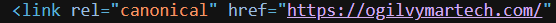
The 'href' attribute tells search engines that the URL in quotes is the original or canonical page that should be used for indexing.
Why are Canonical Tags Important for SEO?
If your website has canonical tags, these prevent duplicate content and consolidate link equity by indicating the primary page.
Let's assume your e-commerce store has two pages of the same product. Then, a canonical tag defines the primary page that Google should crawl and index.
Moreover, search engines penalize websites that have duplicate content, and canonical tags help avoid that penalty.
How to implement canonical tags
Implementing canonicals is a straightforward process. You can add it to your website by modifying the code of a webpage's head section.
Here's a step-by-step process for implementing canonical tags:
- Identify the pages with similar or identical content.
- Choose the preferred URL for indexing.
- Add a canonical tag to the head section of the duplicates.
- Reference the canonical URL as the tag's href value.
Canonicalization Best Practices
Before you implement canonical tags, you must have a clear understanding of canonicalization best practices. Here are some tips you should keep in mind:
01. Canonical URLs
The tag should be used only once per page.
The canonical tag must be referenced on every duplicate page.
The URLs should be lowercase and a valid page in Google's index.
The canonical tag must be added to the head section of the HTML code.
Use canonical tags only if you have two or more identical or similar versions of the same content.
02. Use self-referential Tags
For the URL https://example.com/sample-page the self-referencing canonical would be:
The link is <link rel="canonical" href="https://example.com/sample-page">
03. HTTPS Versions
Canonicalize all the versions of a page, including variations of HTTP/HTTPS and www/non-www versions.
Make sure you don't define any non-SSL (HTTP) URLs in your canonical tags if you migrate to SSL.
04. Absolute Links
According to Google's John Mueller, using relative paths with the rel="canonical" link element is not recommended.
As a result, implement: <link rel=“canonical” href=“https://example.com/sample-page/” />
Instead of: <link rel=“canonical” href=”/sample-page/” />
Dive Deep: Multilingual Website SEO: Best Practices for Technical SEO
How to Avoid Common Canonicalization Mistakes
There are several common mistakes to avoid when implementing canonical tags.
Here are a few critical mistakes to watch out for:
- Avoid using canonical tags on URLs that are non-indexable or non-existent. Otherwise, it will cause a 404 error.
- Not using canonical tags on identical pages can cause duplicate content issues and potentially hurt your SEO rankings.
- Redirecting pages with a 301 rather than implementing a canonical tag can lead to broken links.
- Using a canonical tag to avoid a penalty for thin content or link spam can be seen as deceptive and could lead to a penalty.
How to Find and Fix Canonicalization Issues
If you're experiencing issues with indexing or duplicate content, it may be helpful to identify and fix canonicalization problems. Here are some tools you can use to find and resolve canonicalization issues:
Google Search Console can help you track canonicalization configuration issues and crawl errors.
Screaming Frog SEO Spider can help you determine which pages have canonical tags and whether they're configured correctly.
SEMrush Site Audit tool can also list out the pages with missing canonicals or pages with canonical issues.
If you need to skyrocket your web traffic or boost search rankings, reach out to our team of SEO specialists.
Key Takeaways
Canonical tags are a crucial component of SEO that helps prevent duplicate content issues on your website. By implementing canonical tags, you can help search engines identify which version of a webpage is the original and preferred version.
Implementing canonicalization best practices and avoiding common problems can ensure that your website receives the maximum SEO benefit from canonical tags.
By using the tools and best practices we’ve discussed in this article, you can avoid duplicate content issues, improve your website’s user experience, and dramatically increase your website’s visibility and ranking on search engines like Google and Bing.
Read Next: How Does Duplicate Content Impact SEO?

